MinePilot An End-to-End Automatic Obstacle Avoidance Agent
Video
Project Summary
In this project, we try to solve a sub-problem of the self-driving problem, which is automatic obstacle avoidance. We treat the main character “Steve” as a car. The agent can do the following action:
- Accelerating forward speed
- Reducing forward speed (braking)
- Moving to the left horizontally
- Moving to the right horizontally
- Stop moving horizontally
We want our agent to drive as far as possible without hitting obstacles set on a road in a given period of time (30 seconds). The boundary of the road is surrounded by redstone wall, so the agent must make sure it drive on the road and avoid driving onto the shoulder. The size of the road is 9 by 150, and there are 22 pillars as obstacles on the road. You can see the details of the map from the figure below:

We want to develop our agent in a way similar to modern self-driving solutions. Therefore, we are using Deep Q-learning Network (DQN) with computer vision (image segmentation) to solve this problem. We also set the forward speed of our agent as a continuos variable to simulate the reality. Using machine learning algorithm is essential to solve this problem since in real world, it is very hard to get simple grid representation of roads, and the action space is continuos in the real world. Auto-driving agents can only get complex vision information and limited depth information from cameras and radars.
Approaches
In this project, we use the following models to be baselines or to solve this problem:
- DQN without Segmentation Neural Network (SNN) (baseline 1)
- DQN with SNN. Speed fixed (model in status report. baseline 2)
- DQN with SNN and continuos speed. (final model)
DQN without SNN
Our first baseline is a deep Q-learning network. The reinforcement learning part of this model is identical to our final model. The only difference between this model and the final model is that this model does not use SNN as a vision-preprocessing network. Since this model does not use SNN, it will have more reaction time than models with SNN because SNN is a relative large network, and requires much time to run. However, without SNN, the DQN must learn the representation of the image and the policy at the same time, which can be very hard. Also, since the learning of the DQN is based on a black box reward, the representation in convolutional layers might be very imprecise.
Action
As discussed above, our agent has 5 different actions described below:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Action | Do nothing/End moving horizontally | Horizontal velocity set to -0.25 | Horizontally velocity set to 0.25 | Forward speed +0.1 | Forward speed -0.1 |
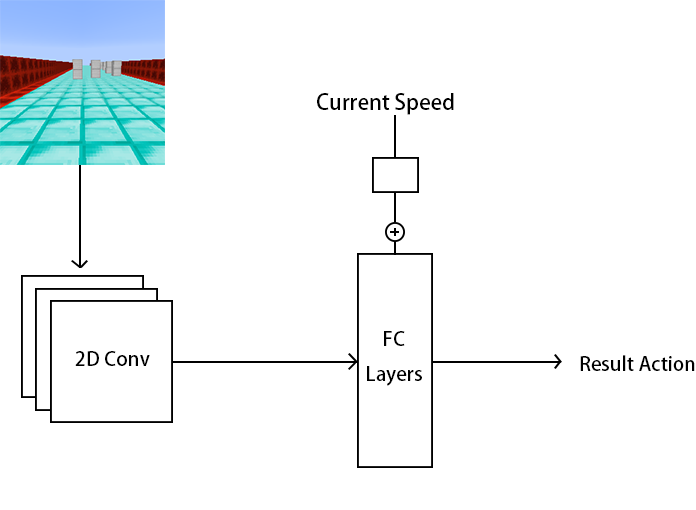
Network Structure
The network contains two parts. The first part is a series 2D convolutional layers with max pooling. They take the original game screen as the input. The second part is fully connected layers. They take the result from the convolutional layers, and the current speed as the input, and output the action.
Reward Function
We want to define a non-sparse reward function. Therefore, we decide to use the current speed of the agent as the main reward. We use the 10 times of the speed subtracted from 1.6 to be the main reward. The reward will be negative if the speed is too slow. Also, we want to encourage our agent to avoid hitting pillars and do less meaningless actions. Therefore, we used reward shaping method, and design the reward function as given below:
where $S$ indicates the forward speed, $S \in [0.1,0.8]$.
Loss Function
The goal of Deep Q-learning is that instead of building a Q table, we want to find a Q function $Q$, and a policy $\pi$, so that $\pi(s)=\underset{s}{\mathrm{argmax}}(Q(s,a))$. $Q$ may be very complex, but according to universal approximation theorem, our network can fit the $Q$. Every epoch, we update the $Q$ by minimizing the loss function given below:
To train our model, we apply the Huber loss upon the $\delta$
We are using Huber loss because it would make the loss not very sensitive to outliers and more stable. The performance of this model is not very good which is described in evaluation.
DQN with SNN (fixed forward speed)
Instead of taking the original image as input directly, we can train another neural network to do the image segmentation. It is very hard for a DQN to learn image representation. However, it will be much easier if we add a neural network which only learns how to represent image. Therefore, in our status report, we present a model which combines DQN and segmentation neural network. We use this model as a baseline here, since it can only change the direction of strafing without changing the forward speed.
In this model, the SNN is used as a sensor of our agent. The representation from SNN is more efficient than original image is because there are only 5 possible values and 1 channel in its output. The 5 values are:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Represents | sky | pillars and walls | grass | shoulder and outline walls | road |
This representation is much more efficient than the original images (3 channels with 256 values).
Data Generation
Since the SNN is trained by using supervised learning. The most important problem is how to get the dataset with enough data. We developed an approach to generate data by ourselves.
First, we generate $n$ random maps ($n=500$ in our case). Then, we replace the resource package of Minecraft to a pure color texture package made by ourselves(shown below)
Then, we just scan the image pixel by pixel, and we set different threshold of RGB values for types of blocks. Then, we final dataset looks like as shown below:


Network Structure and Loss Function
We are using one of the most popular network structure, ResNet50, to do the segmentation. This network can achieve a very high accuracy (See Evaluation). We train the SNN by minimizing the pixel-wise cross entropy between the ground truth and our prediction. The pixel-wise cross entropy function is given below:
We use Adam as the optimizer with learning rate = 0.0002, and trained only 10 epochs with batch size 4 under RTX 2080 graphics cards. After 50 epochs, the validation accuracy reached around 85%.
DQN
The DQN part of this model is almost identical to DQN without SNN. However, the action is defined as:
| 0 | 1 | 2 | |
|---|---|---|---|
| Action | Stop moving horizontally | Move left horizontally | Move right horizontally |
Also, the reward function is defined as:
In this model, the forward speed is fixed at 0.35. When we increase this speed, the agent cannot adapt to the environment if there are obstacles because it cannot reduce its speed. The details can be found in evaluation section.
DQN with SNN and continuos speed
By studying the models we discussed above, we are able to find the best model among the models we trained. First, SNN is critical to this problem, since the DQN should focus on learning the best policy instead of image representation. Also, variable forward speed is required since the agent should reduce its speed if the density of obstacles is high, and increase its speed if there are less obstacles in order to drive as far as possible. Therefore, we combined the DQN without SNN and DQN with SNN (fixed forward speed) to get our final model. The action space and reward function are identical to DQN without SNN, so we will focus on what is different in our final model.
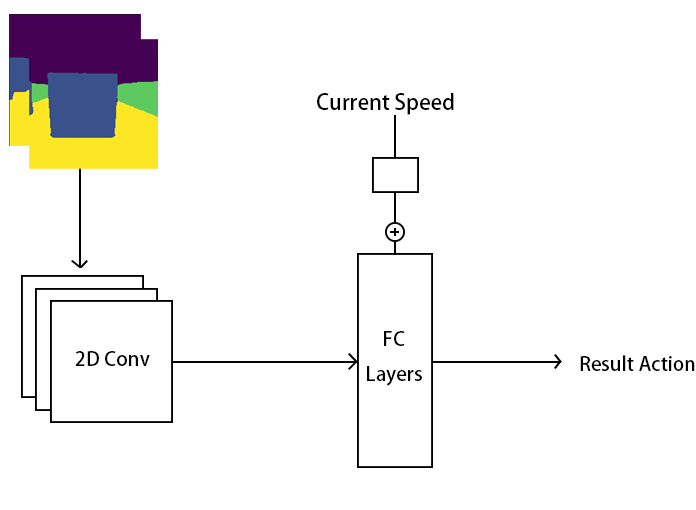
Network Structure
Since now the forward speed is various. The agent needs more information about speed. Therefore, instead of feeding the model a single segmented image. We provide the model two channels of images. One is the current state, the other one is the previous state. The segmented images go through a series of CNN. The result of CNN would be computed by FC with numerical speed jointly. We are using SELU as the activation function except the last layer.
Training
At first, we found it is very hard to train with continuos speed. Therefore, we applied the curriculum learning to help us. We still fixed the length of the road ($9\times 150$), but we adjust the density of the pillars. At first, we only put one pillar in front of our agent and trained the model for 50 epochs. Then, we set 11 pillars on the road, and trained it for 50 epochs. At last, we set 22 pillars on the road, and trained it for 100 epochs to get our final model.
About our hyperparameter, we set our replay memory of DQN to 10000, and use Adam as our optimizer with learning rate = 0.00045 and weight decay = 0.001. We set our $\gamma$ to $0.98$, and the $\epsilon$ is decreasing from $0.88$ to $0.05$.
Evaluation
Segmentation Neural Network
For the SNN, we mainly look into two types of metrics: pixel-wise cross entropy loss, and pixel-wise accuracy.
We trained our for 50 epochs, and we find that the loss converged nicely:
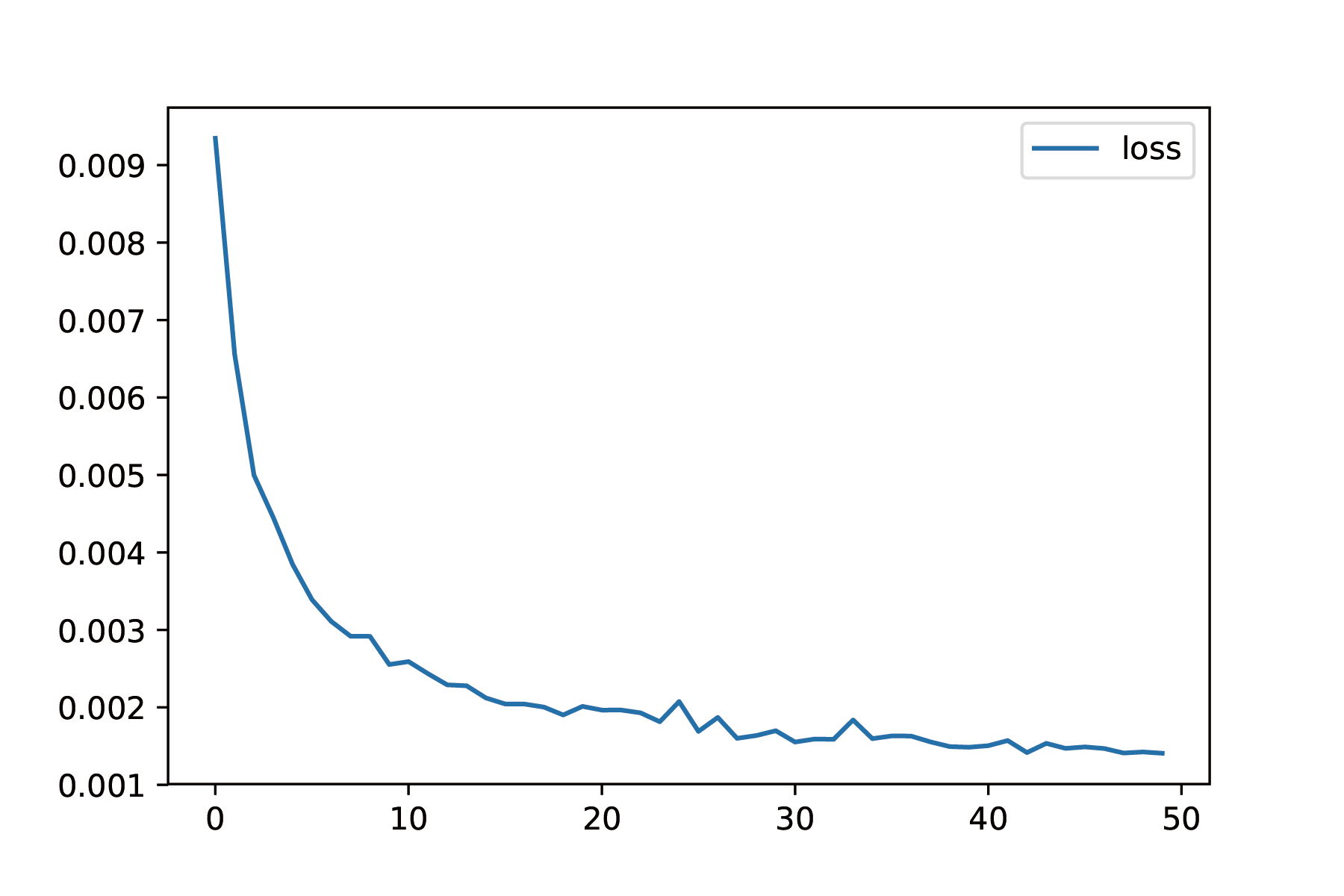
We also tracked the pixel-wise accuracy given by $a=\frac{1}{mn}\sum_{i=0}^n\sum_{j=0}(y_{ij}==\hat{y}_{ij})$. The validation accuracy is a little bit noisy but it is increasing, and reached $86\%$ which is good enough for us.
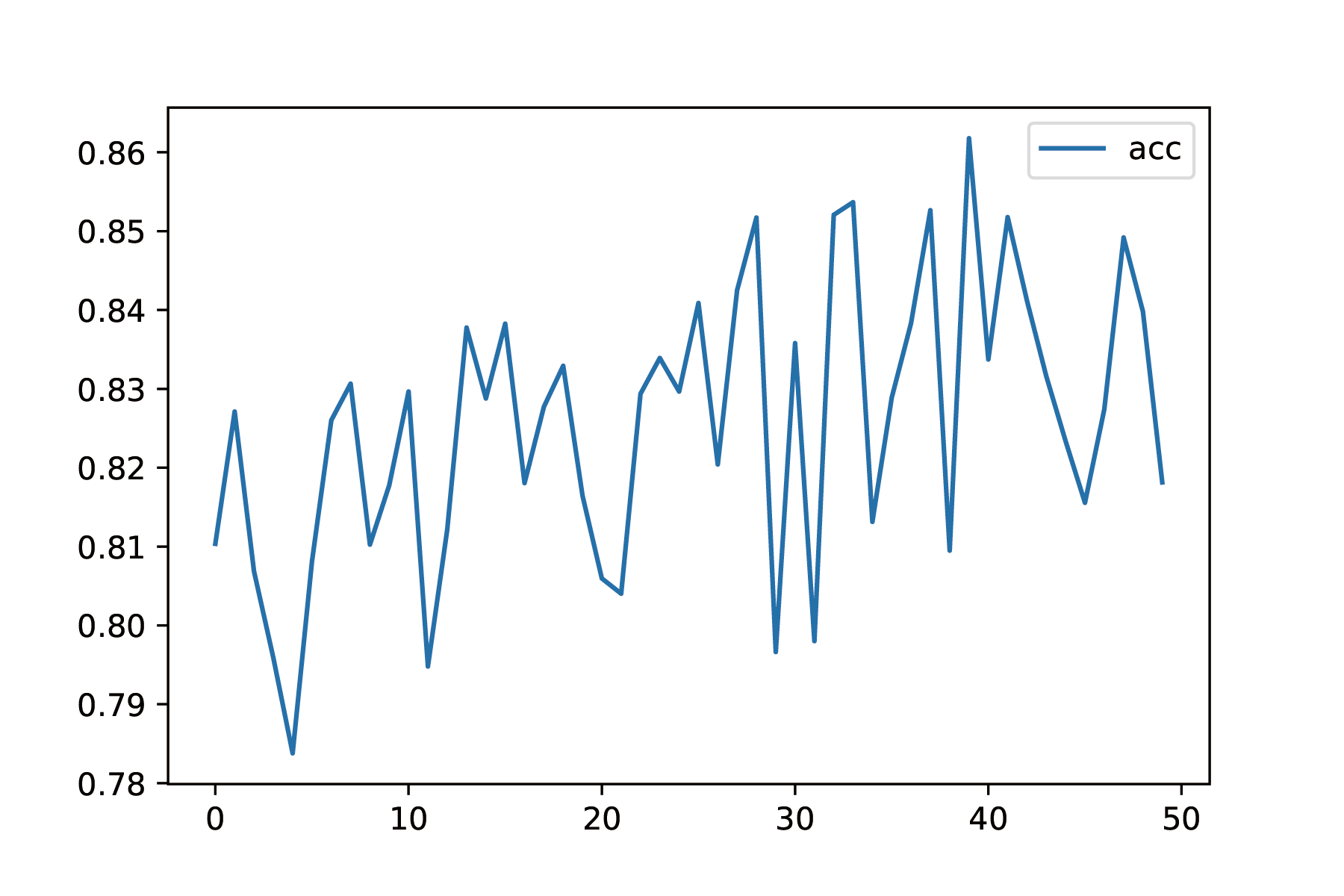
You can also visually see that the performance of SNN is good:

DQN
For DQN, we look at two metrics: how far the distances the agents drive, and how rewards change.
The most important metric is the distance. We choose a random generated map, and try all three agents on that map for 75 epochs, and we record the distance the agent drove. The result is shown below:
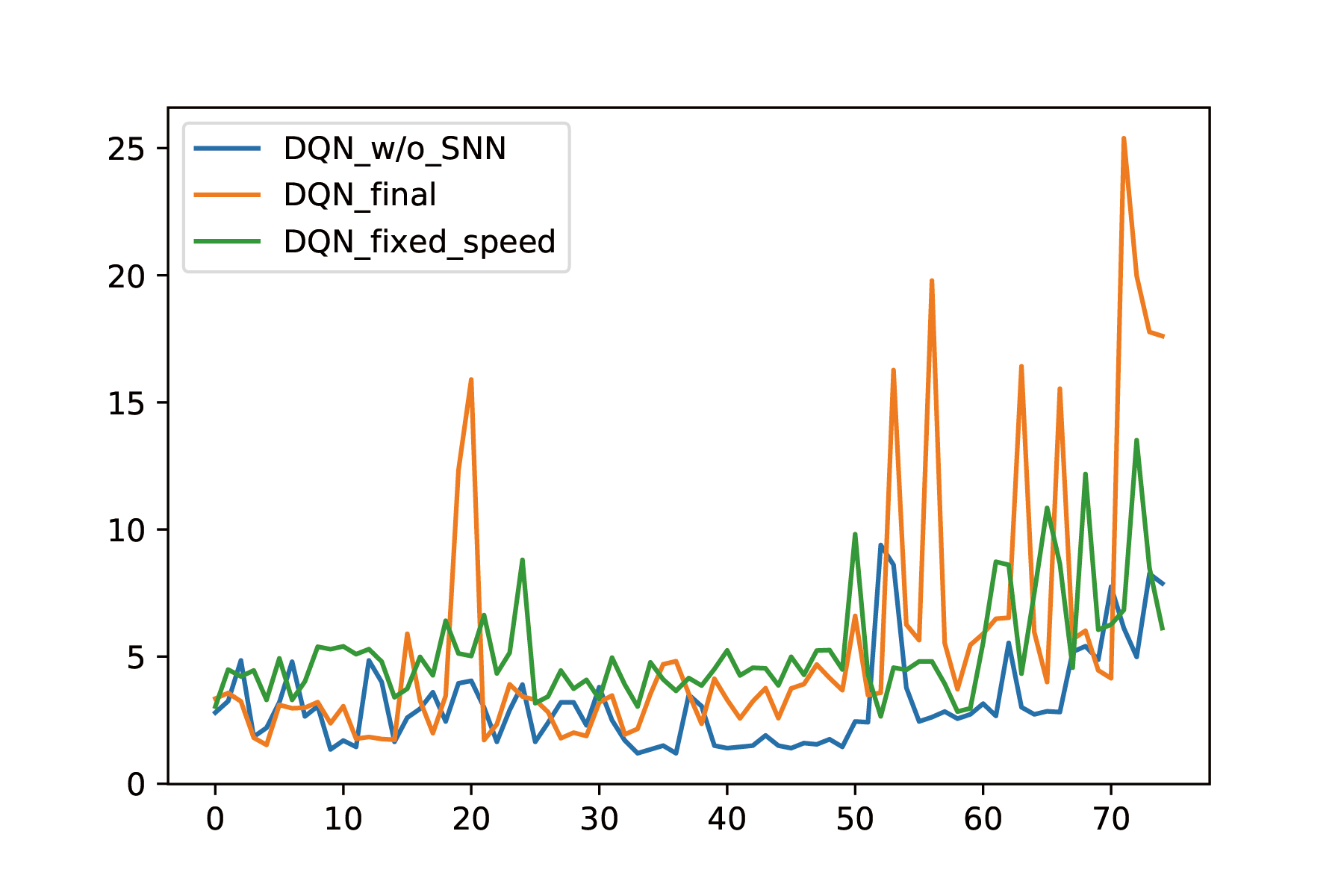
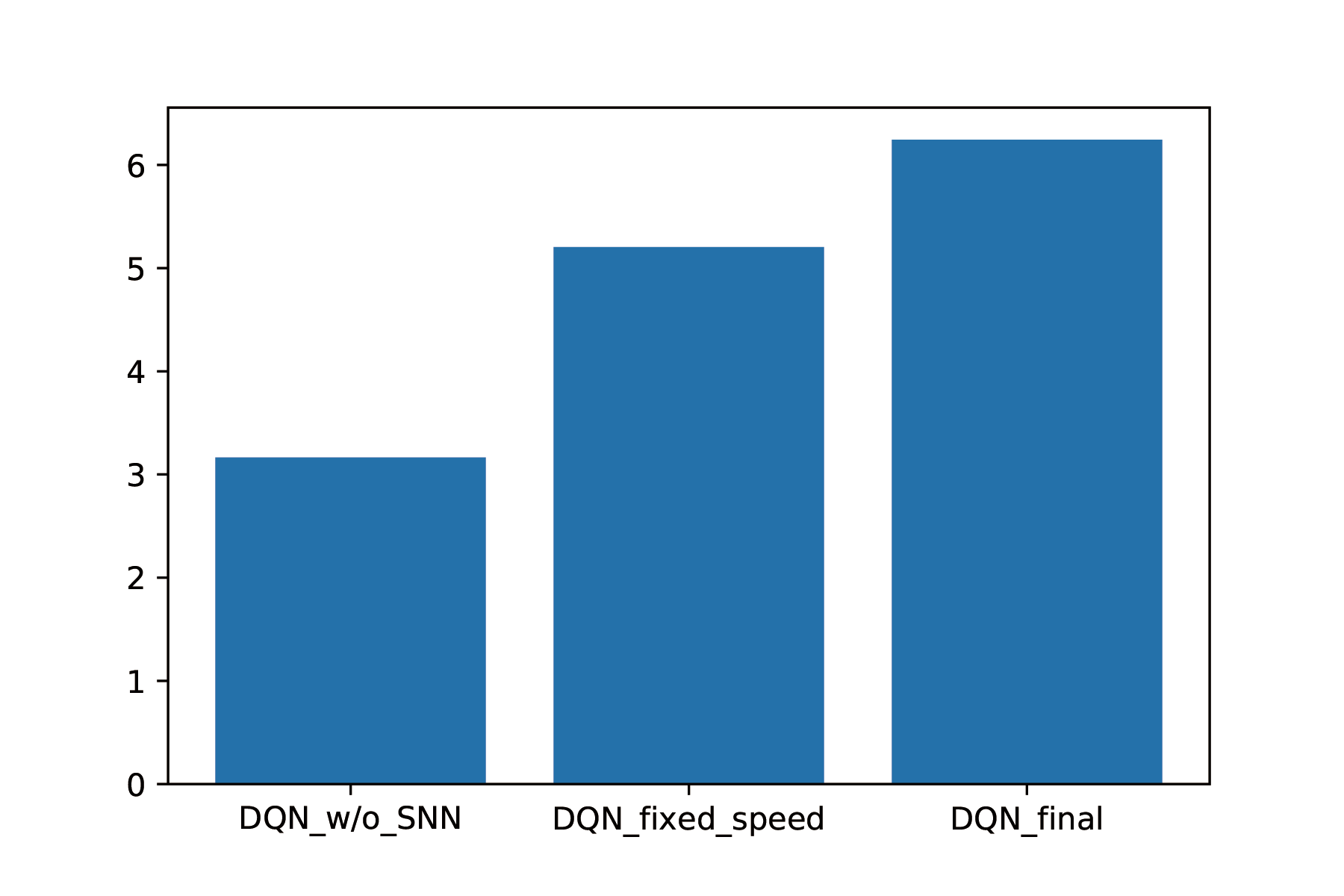
The found that the DQN without SNN performed the worst. It basically hits obstacles in a very short time. The DQN with SNN and fixed speed can avoid obstacles, but since its speed is fixed at $0.3$, it cannot drive very far. The DQN with SNN and variable speed is the best. It can reduce its speed when the density of obstacles is high, and increase its speed when the density is low,as shown in the video. The mean distance is also given below:
We did another experiment. We randomly generate 10 maps, and trained our three models on them, and we record the maximum distance those three models can achieve. The result is given below:
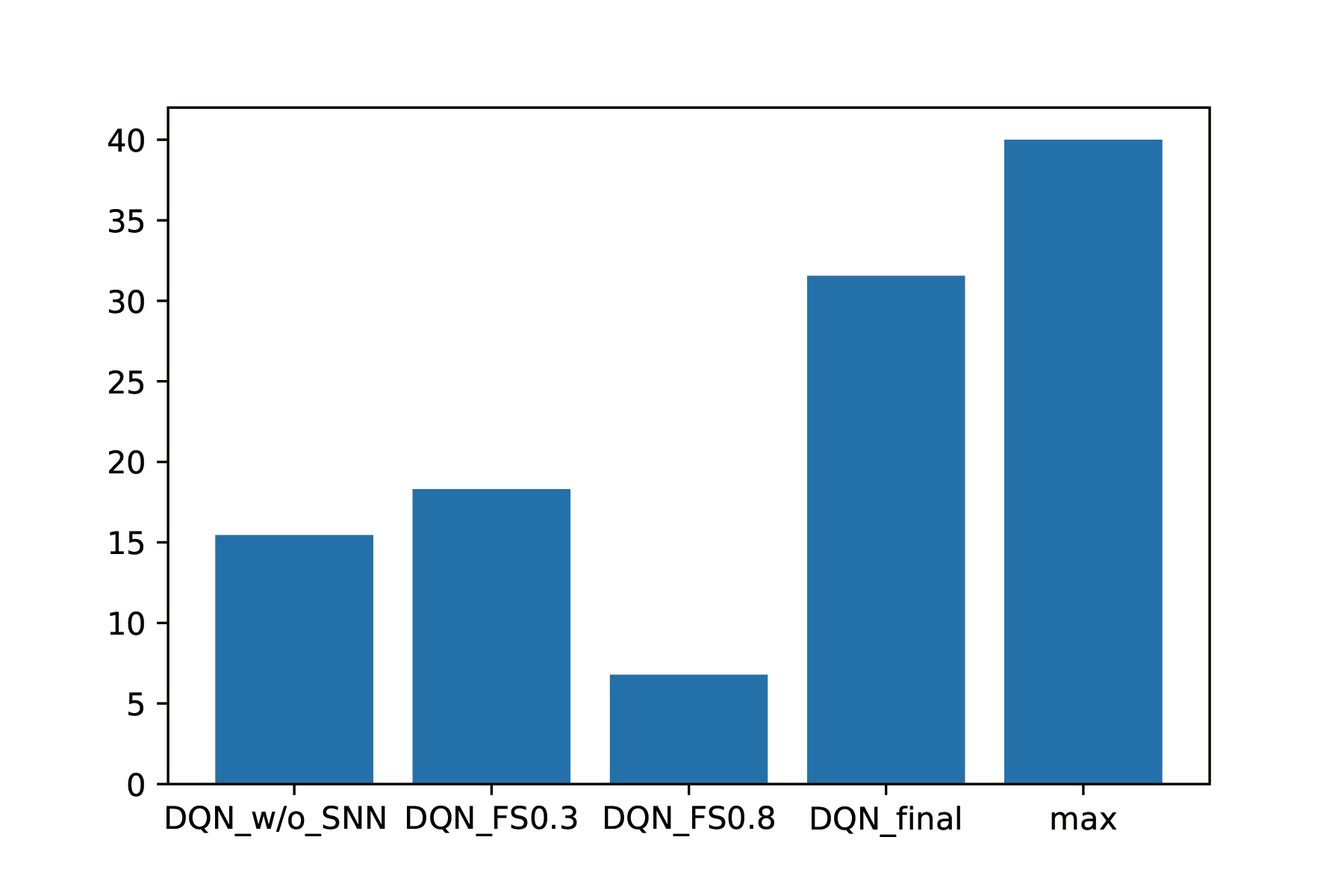
We find that our final model can reached the farthest distance among three models (31.55). In our metrics, the theoretical farthest distance a model can reach in 30 seconds is 40;therefore, our final model has achieved a very good performance. We also tired to revise the speed of DQN with SNN and fixed speed. We found that if we set the speed of that model to the maximum speed (0.8), it achieves the worst distance among our models. It is caused by that it does no have enough time to avoid obstacles since the speed is too high.
We also look into the rewards. We found that the trend of the rewards is pretty similar to the distance, which is understandable because we basically use the distance as the rewards, but add some reward shaping terms:
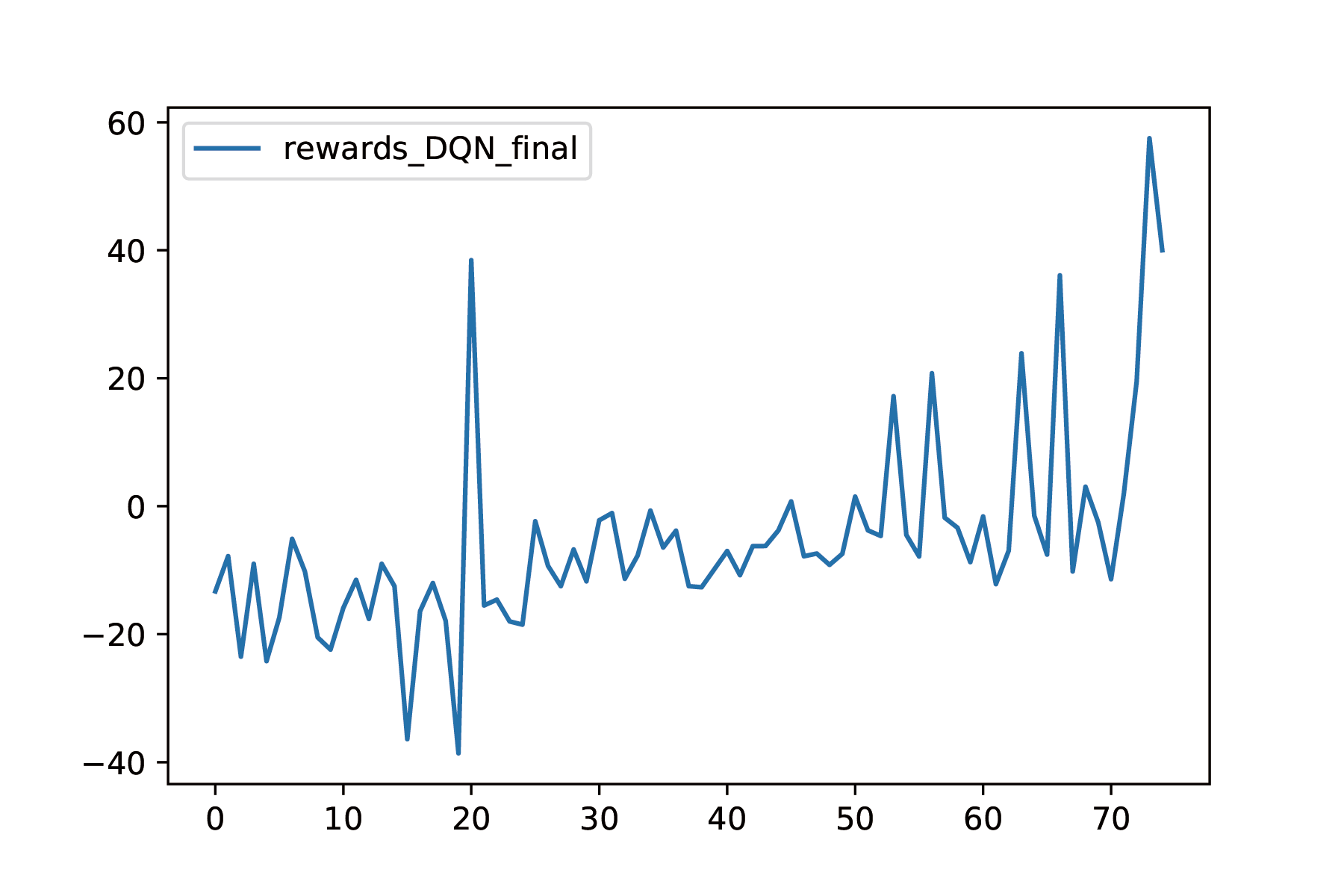
From the evaluation above, we are confident that our final DQN model basically solves the obstacle auto-avoidance problem under Minecraft setting.
References
We have used Python Malmo module to simulate the car driving environment and to operate the Minecraft agent. We use PyTorch library to train our agent to avoid obstacles.
The implementation of our DQN take this as a reference.
The ResNet50 we are using is introduced in this this paper.
The Steven image on home page is from this source